- Ashish Batwara
You have been asked to build integrations for your GRC platform. Seems straightforward: call some APIs, normalize the data, display it in the UI. A few weeks of work, tops.
Except it is not a few weeks. And it is not straightforward.
If you have built production-grade integrations before, you know. If you have not, this post will save you months of painful discovery. Building a multi-tenant integration layer that actually works requires solving a dozen hard problems that are not obvious until you are knee-deep in them.
What "Production-Grade" Actually Means
A proof-of-concept integration is easy. You read the API docs, make some calls, parse the response. Done in a day.
A production integration is different. Here is what you actually need to handle:
Authentication
Every vendor does authentication differently. OAuth 2.0 with refresh tokens. API keys with different header formats. Service accounts. JWT tokens. Some require IP allowlisting. Some rotate credentials automatically. Some have different auth for different endpoints.
You need to handle all of these. And you need to handle token refresh without interrupting data syncs. And you need to store credentials securely for hundreds or thousands of customer connections.
Rate Limiting
Every API has rate limits. Some are documented. Some are not. Some return 429 errors with retry-after headers. Some just return 500 errors when you hit the limit. Some have per-endpoint limits. Some have daily quotas.
When you are pulling data for hundreds of customers, rate limits become a constant constraint. You need queuing, backoff strategies, and intelligent scheduling.
Pagination
Some APIs use offset pagination. Some use cursor pagination. Some use link headers. Some have inconsistent pagination across endpoints. Some return incomplete pages under load. Some change pagination behavior between API versions. You need to handle all of these correctly, or you will miss data.
Error Handling
Network timeouts. 500 errors. Malformed responses. Unexpected schema changes. Deprecated endpoints. Maintenance windows. You need retry logic with exponential backoff. You need circuit breakers so one failing integration does not take down your whole system. You need alerting so you know when something breaks.
Data Normalization
CrowdStrike calls them “detections.” SentinelOne calls them “threats.” Microsoft Defender calls them “incidents.” They all mean roughly the same thing, but the schemas are completely different. Field names, data types, nested structures, timestamp formats.
For GRC platforms, this is not just about making data readable. It is about producing evidence signals that map cleanly to SOC 2, ISO 27001, and NIST CSF controls. Your platform needs Normalized Evidence Signals, not raw vendor logs. That requires Unified APIs that understand security categories at a semantic level, not just field-level mapping.
Real-Time Events
Security does not wait for your cron job. Threats happen in real-time, and your customers expect Continuous Control Monitoring, not periodic batch pulls.
Some vendors support webhooks. Some do not. The ones that do all have different payload formats, different authentication methods, different retry policies. You end up building a custom event handler for each vendor, plus queuing infrastructure, plus deduplication logic, plus delivery guarantees. That is a full-time job for a team, not a feature.
A proper Webhook Exchange handles all of this. You register one webhook endpoint and receive normalized events from every connected vendor in a consistent format.
AI-Native Access
If you are building AI features (and you probably are, or will be), your models need data. The traditional approach is to build a REST API layer, handle authentication, implement pagination, parse responses, and normalize everything before feeding it to the model. That is a lot of glue code.
The Model Context Protocol (MCP) is a standard that lets AI models discover and use tools directly. An MCP Server exposes security data as discoverable tools, so your AI can query “Show me all endpoints missing EDR coverage” without any glue code. The data comes back already normalized.
Schema Drift
Even when APIs do not officially change, the data inside them does. New fields appear. Optional fields become populated. Enum values expand. Your normalization logic needs to handle this gracefully.
Schema Studio solves this with elastic schemas that adapt as vendors evolve, so you are not locked into rigid mappings that break when APIs change.
The Multi-Tenant Complexity
All of the above gets harder when you are running integrations for multiple customers simultaneously.
Tenant Isolation
Customer A’s data can never leak to Customer B. This sounds obvious, but it is easy to get wrong. Shared rate limit pools, shared caching layers, shared error logs. Any of these can become vectors for data leakage if you are not careful.
Credential Management
You are storing API credentials for hundreds of customer connections. These need to be encrypted at rest and in transit. Access needs to be tightly controlled. Audit logs need to track every credential access. If you are pursuing SOC 2 for your own platform (and you probably are), your credential storage needs to pass auditor scrutiny.
Scaling
One customer with one CrowdStrike connection is manageable. A hundred customers with connections to ten different tools each is a thousand concurrent integrations. Each with its own sync schedule, rate limits, and failure modes. Your architecture needs to handle this without falling over.
The Maintenance Burden Nobody Warns You About
Building the integration is maybe 30% of the work. The other 70% is maintenance.
API Versioning
Vendors update their APIs. Sometimes they give you warning. Sometimes they do not. CrowdStrike moves from v1 to v2. Okta deprecates an endpoint. AWS changes their signature algorithm. Each change requires code updates, testing, and deployment. Multiply by 40 integrations, and you are dealing with changes constantly.
Breaking Changes
The worst kind of API change is the undocumented one. A field that used to be a string is now an array. A timestamp format changes. A required parameter becomes optional (or vice versa). These break your integration silently. You do not know until customers complain or data stops flowing.
The Security Requirements
You are building a GRC platform. Your customers are security-conscious. Your integration layer needs to meet their security requirements.
No agents. Most security teams will not install software that has write access to their security tools. Read-only API access is table stakes.
Credential security. Encryption at rest, encryption in transit, access controls, audit logging. Your credential storage is a high-value target.
Data residency. Some customers require data to stay in specific regions. Your integration layer needs to support this.
Audit trails. Who accessed what data, when, and why. Every API call needs logging.
Building all of this is essentially building a second product. A product that generates no direct revenue but consumes significant engineering resources.
The Build vs. Buy Calculation
So should you build this yourself or use an existing infrastructure that supports all these?
Arguments for building:
Full control over the implementation. No external dependencies. Custom behavior for specific use cases.
Arguments against building:
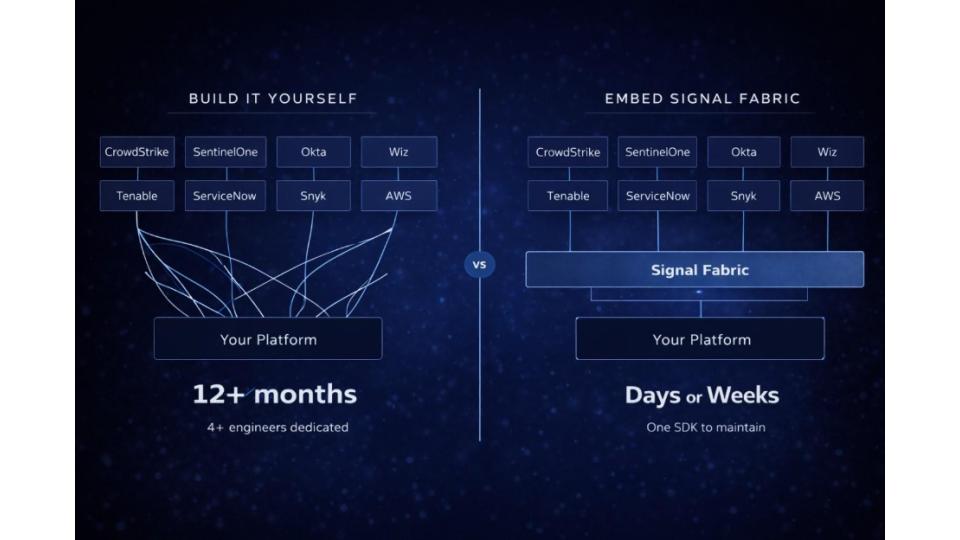
Support 20 vendors across a full engineering team (dev, QA, DevOps, infra): 12+ months minimum. A team of 4+ engineers working full-time just on integrations.
2+ FTEs ongoing for maintenance. You are not an integration company. This is not your core competency. Time to market: months or quarters vs. days or weeks. Every hour spent on integrations is an hour not spent on the compliance logic that wins your market.
Early-stage teams lose 40-50% of their engineering capacity to integration work. Scaled teams look more efficient by percentage, but they are spending millions of dollars annually on integration maintenance. The math usually favors buying (or embedding) unless integrations are literally your core product.
What Embedding a Signal Fabric Looks Like
When you embed signal infrastructure, here is what changes:
For your platform:
Embed a Connect UI component. Your customers use this to authenticate their tools. Call one API to get Normalized Evidence Signals across all tools in a category. Handle one schema instead of dozens. Receive real-time events through the Webhook Exchange. Expose data to AI through MCP.
For your customers:
They connect their tools through a familiar OAuth flow. They do not install agents or grant write access. Their data flows into your platform automatically, in real-time.
For your engineering team:
No more debugging vendor API changes. No more managing credentials for hundreds of connections. No more building pagination, rate limiting, and retry logic for each vendor. No more building webhook infrastructure. No more worrying about schema drift.
The Bigger Picture: Operational Context
Here is something that is easy to miss when you are focused on the mechanics of integration: the goal is not just to move data. The goal is to give your platform operational context.
Operational context means a shared, consistent understanding of what is actually true across your customer’s security environment. Who is this identity? What systems exist? What is enforced versus merely configured? What changed, and when?
You cannot build this operational context if you are spending all your engineering capacity on plumbing. And you cannot deliver Continuous Control Monitoring without it.
This is why the build vs. buy decision matters more than it seems. It is not just about saving engineering time. It is about whether your platform can deliver the operational foundation that modern GRC requires.
Make the Decision With Real Numbers
Building a production-grade, multi-tenant integration layer is harder than it looks. Most teams underestimate the initial build, dramatically underestimate the maintenance burden, and do not account for the opportunity cost of engineers not working on product.
Before you decide to build, run the numbers. How many integrations do you need? What is the fully-loaded cost of an engineer on your team? How much maintenance are you signing up for? Refer to our integration cost calculator at https://unizo.ai/diy-integration-cost-calculator/ to calculate the integration cost yourself.
Then compare that to the cost of embedding an existing solution. The answer is usually clear.
Want to see what embedding looks like? Find more information at https://hub.unizo.ai/grc and book a demo.
Related Reading:
For a deeper look at how Unified APIs, Webhook Exchange, and MCP Server work together, see our series “From Security Chaos to AI-Ready Context” on unizo.ai.



